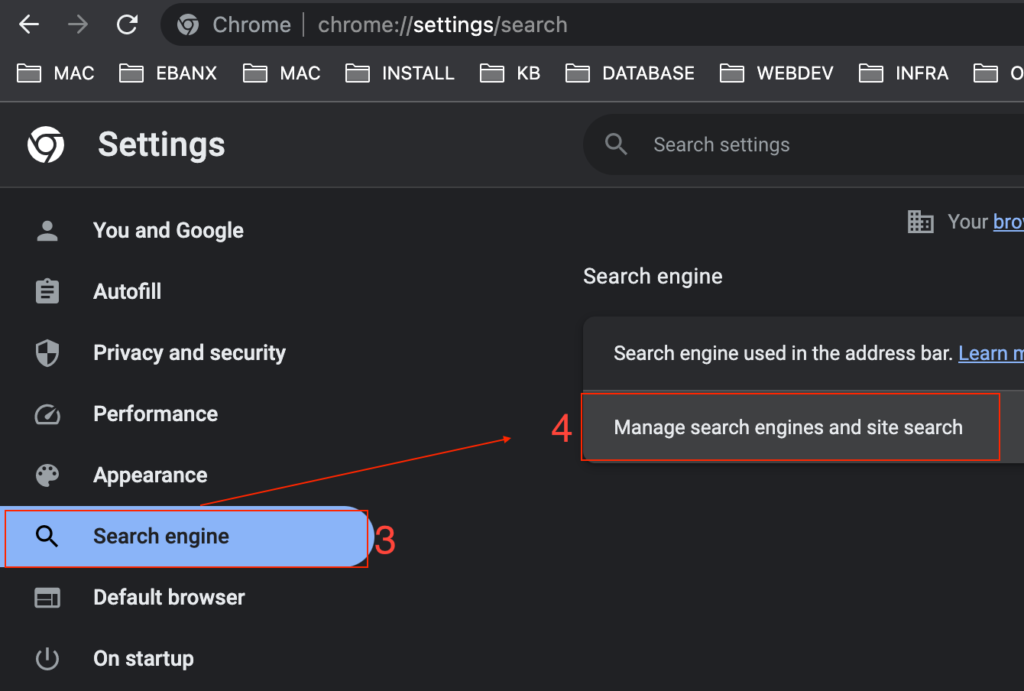
$string_date = '2010-08-07 08:39:00';
[$y, $m, $d] = [null, null, null];
switch(true) {
case preg_match('/^(\d{4})-(\d{2})-(\d{2})/', $string_date, $fragments):
list($y, $m, $d) = [$fragments[1], $fragments[2], $fragments[3]];
break;
case preg_match('/^(\d{4})\/(\d{2})\/(\d{2})/', $string_date, $fragments):
list($y, $m, $d) = [$fragments[1], $fragments[2], $fragments[3]];
break;
case preg_match('/^(\d{2})-(\d{2})-(\d{4})/', $string_date, $fragments):
list($d, $m, $y) = [$fragments[1], $fragments[2], $fragments[3]];
break;
case preg_match('/^(\d{2})\/(\d{2})\/(\d{4})/', $string_date, $fragments):
list($m, $d, $y) = [$fragments[1], $fragments[2], $fragments[3]];
break;
default:
throw new Exception('String Date supplied with unknown format');
}
if (!checkdate($m, $d, $y)) {
throw new Exception ('String Date supplied with invalid date content');
}
try {
$object_datetime = new DateTime($string_date);
} catch (\Exception $exception) {
echo 'String Date supplied impossible to convert to Date';
$object_datetime = null;
}
null !== $object_date
? $object_date->setTime(0,0)
; null;
var_dump($object_datetime);
Pessoal, este código surgiu da necessidade de se converter um campo de data fornecido como string numa integração entre sistemas.
O fato é que quando se depende de informações externas o processo pode facilmente quebrar quando as regras estabelecidas não forem estritamente respeitadas.
No meu caso um campo que deveria ser enviado no formato date Y-m-d acabou sendo enviado num formato DateTime Y-m-d H:i:s. O problema se agravou pelo fato de que apenas um dos fornecedores acabou enviando desta forma e os demais fornecedores enviavam a informação no formato acordado.
Dúvida cruel… solicitar ao fornecedor para corrigir o envio da informação? Ou flexibilizar a entrada do dados de forma inteligente?
Opção dois na veia! O fato é que todos os fornecedores continuavam enviando uma data válida pra nós, só que com formatos ou máscaras diferentes, mas ainda assim eram datas válidas.
Baseado neste preceito a solução foi substituir a criação do objeto DateTime calcada no createFromFormat a partir de máscaras previamente conhecidas por simplesmente passar a string date recebida para o construtor do DateTime.
// stop creating date based on known format, this will fail when datetime content is sent
$object_datetime = DateTime::createFromFormat('Y-m-d', $string_date);
// start creating datetime based on constructor, this will work with any valid date/time content
$object_datetime = new DateTime($string_date);
A grande sacada consiste em validar se uma data válida foi enviada, no caso fazemos esta validação para a porção Y-m-d somente. Se a validação passar neste nível a probabilidade da informação ser uma data válida inclusive na sua porção hora será muito grande.
Para exemplificar a flexibilidade de entrada desta informação, segue abaixo alguns exemplos de formatos válidos que irão funcionar com o construtor.
$object_datetime = new DateTime('2010-08');
var_dump($object_datetime); //2010-08-01 00:00:00.000000
$object_datetime = new DateTime('2010-08 08:39');
var_dump($object_datetime); //2010-08-01 08:39:00.000000
$object_datetime = new DateTime('2010-08 08:39:53');
var_dump($object_datetime); //2010-08-01 08:39:53.000000
$object_datetime = new DateTime('2010-08T08:39:53Z');
var_dump($object_datetime); //2010-08-01 08:39:53.000000
$object_datetime = new DateTime('2010-08-07');
var_dump($object_datetime); //2010-08-07 00:00:00.000000
$object_datetime = new DateTime('2010-08-07 08:39');
var_dump($object_datetime); //2010-08-07 08:39:00.000000
$object_datetime = new DateTime('2010-08-07 08:39:53');
var_dump($object_datetime); //2010-08-07 08:39:53.000000
$object_datetime = new DateTime('2010-08-07T08:39:53Z');
var_dump($object_datetime); //2010-08-07 08:39:53.000000
Considere ainda que podemos receber barras ao invés de hífen como separador que irá funcionar corretamente com todas as variações acima apresentadas.
$object_datetime = new DateTime('2010/08/07 08:39:53');
var_dump($object_datetime); //2010-08-07 08:39:53.000000
$object_datetime = new DateTime('2010/08/07T08:39:53Z');
var_dump($object_datetime); //2010-08-07 08:39:53.000000
Outra grande vantagem de se utilizar o construtor do DateTime é que ele vai funcionar com o formato nativo americano m/d/Y quando separado por barras e com o formato nativo britânico m-d-Y quando separado por hífens.
$object_datetime = new DateTime('08/07/2010 08:39:53');
var_dump($object_datetime); //2010-08-07 08:39:53.000000
$object_datetime = new DateTime('07-08-2010 08:39:53');
var_dump($object_datetime); //2010-08-07 08:39:53.000000
Lembrando que em nenhum momento tivemos que informar máscaras de formatação para efetivamente criar o objeto DateTime. Simplesmente mandamos a string date para o construtor e pronto.
E caso a informação final deva ser uma data sem a porção hora, simplesmente zeramos esta porção depois do objeto criado, assim:
$object_datetime = new DateTime('08/07/2010 08:39:53');
var_dump($object_datetime); //2010-08-07 08:39:53.000000
$object_datetime->setTime(0,0);
var_dump($object_datetime); //2010-08-07 00:00:00.000000
Depois desta demonstração de flexibilidade de formatos acredito que as vantagens de criação do DateTime utilizando o construtor tenham ficado claras.
E é claro que o código do início do artigo merece um refactoring para ser mais CleanCode e também para suportar os demais formatos aceitos pelo construtor do DateTime, mas para fins didáticos preferi mantê-lo mais simples mesmo.
E agora? Troca ou não troca o DateTime::createFromFormat pelo new DateTime constructor? Você decide…
Happy code!